The mathematical expectation a=3 and the standard deviation =5 of a normally distributed random variable X are given.
Write down the probability distribution density and schematically plot it.
Find the probability that x will take a value from the interval (2;10).
Find the probability that x will take a value greater than 10.
Find an interval symmetrical with respect to the mathematical expectation, in which the values of the quantity x will be contained with probability =0.95.
1). Let's compose the distribution density function of a random variable X with parameters а=3, =5 using the formula
 . Let's construct a schematic graph of the function
. Let's construct a schematic graph of the function  . Let us pay attention to the fact that the normal curve is symmetrical with respect to the straight line x = 3 and has max at this point equal to
. Let us pay attention to the fact that the normal curve is symmetrical with respect to the straight line x = 3 and has max at this point equal to  , i.e.
, i.e.  and two inflection points
and two inflection points  with ordinate
with ordinate 
Let's build a graph 
2) Let's use the formula: 
The function values are found from the application table.
4) Let's use the formula 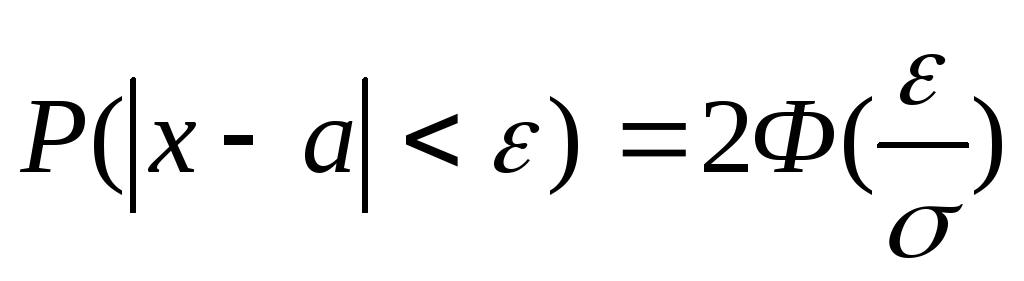 . According to the condition, the probability of falling into an interval symmetrical with respect to the mathematical expectation
. According to the condition, the probability of falling into an interval symmetrical with respect to the mathematical expectation  . Using the table, we find t at which Ф(t)=0.475, t=2. Means
. Using the table, we find t at which Ф(t)=0.475, t=2. Means  . Thus,
. Thus,  . The answer is x(-1;7).
. The answer is x(-1;7).
To problems 31-40.
Find a confidence interval for an estimate with a reliability of 0.95 of the unknown mathematical expectation a of a normally distributed characteristic X population, if the general standard deviation =5, the sample mean  and sample size n=25.
and sample size n=25.
We need to find a confidence interval  .
.
All quantities except t are known. Let's find t from the ratio Ф(t)=0.95/2=0.475. Using the appendix table we find t=1.96. Substituting, we finally get the desired confidence interval of 12.04 The technical control department checked 200 batches of identical products and received the following empirical distribution, frequency n i - the number of batches containing x i non-standard products. It is required to test the hypothesis at a significance level of 0.05 that the number of non-standard products X is distributed according to Poisson's law. Let's find the sample mean: Let us take the sample mean =0.6 as an estimate of the parameter of the Poisson distribution. Therefore, the assumed Poisson's law Setting i=0,1,2,3,4, we find the probabilities P i of the appearance of i non-standard products in 200 batches: Let's find the theoretical frequencies using the formula Let's compare the empirical and theoretical frequencies using the Pearson test. To do this, we will create a calculation table. Let's combine small frequencies (4+2=6) and the corresponding theoretical frequencies (3.96+0.6=4.56). In practice, most random variables that are influenced by a large number of random factors obey the normal probability distribution law. Therefore, in various applications of probability theory, this law is of particular importance. The random variable $X$ obeys the normal probability distribution law if its probability distribution density has the following form $$f\left(x\right)=((1)\over (\sigma \sqrt(2\pi )))e^(-(((\left(x-a\right))^2)\over ( 2(\sigma )^2)))$$ The graph of the function $f\left(x\right)$ is shown schematically in the figure and is called “Gaussian curve”. To the right of this graph is the German 10 mark banknote, which was used before the introduction of the euro. If you look closely, you can see on this banknote the Gaussian curve and its discoverer, the greatest mathematician Carl Friedrich Gauss. Let's return to our density function $f\left(x\right)$ and give some explanations regarding the distribution parameters $a,\ (\sigma )^2$. The parameter $a$ characterizes the center of dispersion of the values of a random variable, that is, it has the meaning of a mathematical expectation. When the parameter $a$ changes and the parameter $(\sigma )^2$ remains unchanged, we can observe a shift in the graph of the function $f\left(x\right)$ along the abscissa, while the density graph itself does not change its shape. The parameter $(\sigma )^2$ is the variance and characterizes the shape of the density graph curve $f\left(x\right)$. When changing the parameter $(\sigma )^2$ with the parameter $a$ unchanged, we can observe how the density graph changes its shape, compressing or stretching, without moving along the abscissa axis. As is known, the probability of a random variable $X$ falling into the interval $\left(\alpha ;\ \beta \right)$ can be calculated $P\left(\alpha< X < \beta \right)=\int^{\beta }_{\alpha }{f\left(x\right)dx}$. Для нормального распределения случайной величины $X$ с параметрами $a,\ \sigma $ справедлива следующая формула: $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right)$$ Here the function $\Phi \left(x\right)=((1)\over (\sqrt(2\pi )))\int^x_0(e^(-t^2/2)dt)$ is the Laplace function . The values of this function are taken from . The following properties of the function $\Phi \left(x\right)$ can be noted. 1
. $\Phi \left(-x\right)=-\Phi \left(x\right)$, that is, the function $\Phi \left(x\right)$ is odd. 2
. $\Phi \left(x\right)$ is a monotonically increasing function. 3
. $(\mathop(lim)_(x\to +\infty ) \Phi \left(x\right)\ )=0.5$, $(\mathop(lim)_(x\to -\infty ) \ Phi \left(x\right)\ )=-0.5$. To calculate the values of the function $\Phi \left(x\right)$, you can also use the function $f_x$ wizard in Excel: $\Phi \left(x\right)=NORMDIST\left(x;0;1;1\right )-0.5$. For example, let's calculate the values of the function $\Phi \left(x\right)$ for $x=2$. The probability of a normally distributed random variable $X\in N\left(a;\ (\sigma )^2\right)$ falling into an interval symmetric with respect to the mathematical expectation $a$ can be calculated using the formula $$P\left(\left|X-a\right|< \delta \right)=2\Phi \left({{\delta }\over {\sigma }}\right).$$ Three sigma rule. It is almost certain that a normally distributed random variable $X$ will fall into the interval $\left(a-3\sigma ;a+3\sigma \right)$. Example 1
. The random variable $X$ is subject to the normal probability distribution law with parameters $a=2,\ \sigma =3$. Find the probability of $X$ falling into the interval $\left(0.5;1\right)$ and the probability of satisfying the inequality $\left|X-a\right|< 0,2$. Using the formula $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right),$$ we find $P\left(0.5;1\right)=\Phi \left(((1-2)\over (3))\right)-\Phi \left(((0.5-2)\ over (3))\right)=\Phi \left(-0.33\right)-\Phi \left(-0.5\right)=\Phi \left(0.5\right)-\Phi \ left(0.33\right)=0.191-0.129=$0.062. $$P\left(\left|X-a\right|< 0,2\right)=2\Phi \left({{\delta }\over {\sigma }}\right)=2\Phi \left({{0,2}\over {3}}\right)=2\Phi \left(0,07\right)=2\cdot 0,028=0,056.$$ Example 2
. Suppose that during the year the price of shares of a certain company is a random variable distributed according to the normal law with a mathematical expectation equal to 50 conventional monetary units and a standard deviation equal to 10. What is the probability that on a randomly selected day of the period under discussion the price for the promotion will be: a) more than 70 conventional monetary units? b) below 50 per share? c) between 45 and 58 conventional monetary units per share? Let the random variable $X$ be the price of shares of a certain company. By condition, $X$ is subject to a normal distribution with parameters $a=50$ - mathematical expectation, $\sigma =10$ - standard deviation. Probability $P\left(\alpha< X < \beta \right)$ попадания $X$ в интервал $\left(\alpha ,\ \beta \right)$ будем находить по формуле: $$P\left(\alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right).$$ $$а)\ P\left(X>70\right)=\Phi \left(((\infty -50)\over (10))\right)-\Phi \left(((70-50)\ over (10))\right)=0.5-\Phi \left(2\right)=0.5-0.4772=0.0228.$$ $$b)\P\left(X< 50\right)=\Phi \left({{50-50}\over {10}}\right)-\Phi \left({{-\infty -50}\over {10}}\right)=\Phi \left(0\right)+0,5=0+0,5=0,5.$$ $$in)\ P\left(45< X < 58\right)=\Phi \left({{58-50}\over {10}}\right)-\Phi \left({{45-50}\over {10}}\right)=\Phi \left(0,8\right)-\Phi \left(-0,5\right)=\Phi \left(0,8\right)+\Phi \left(0,5\right)=$$ Without exaggeration, it can be called a philosophical law. Observing various objects and processes in the world around us, we often come across the fact that something is not enough, and that there is a norm: What examples can you give? There are simply darkness of them. This is, for example, the height, weight of people (and not only), their physical strength, mental abilities, etc. There is a "main mass" (for one reason or another) and there are deviations in both directions. These are different characteristics of inanimate objects (same size, weight). This is a random duration of processes, for example, the time of a hundred-meter race or the transformation of resin into amber. From physics, I remembered air molecules: some of them are slow, some are fast, but most move at “standard” speeds. Next, we deviate from the center by one more standard deviation and calculate the height: Marking points on the drawing (green) and we see that this is quite enough. At the final stage, carefully draw a graph, and especially carefully reflect it convex/concave! Well, you probably realized a long time ago that the x-axis is horizontal asymptote, and it is absolutely forbidden to “climb” behind it! When filing a solution electronically, it’s easy to create a graph in Excel, and unexpectedly for myself, I even recorded a short video on this topic. But first, let's talk about how the shape of the normal curve changes depending on the values of and. When increasing or decreasing "a" (with constant “sigma”) the graph retains its shape and moves right/left respectively. So, for example, when the function takes the form In case of change of "sigma" (with constant “a”), the graph “stays the same” but changes shape. When enlarged, it becomes lower and elongated, like an octopus stretching its tentacles. And, conversely, when decreasing the graph becomes narrower and taller- it turns out to be a “surprised octopus”. Yes, when decrease“sigma” twice: the previous graph narrows and stretches up twice: A normal distribution with a unit sigma value is called normalized, and if it is also centered(our case), then such a distribution is called standard. It has an even simpler density function, which has already been found in Laplace's local theorem: Well, now let's watch the movie:
Yes, absolutely right - somehow undeservedly it remained in the shadows probability distribution function. Let's remember her definition: Inside the integral, a different letter is usually used so that there are no “overlaps” with the notation, because here each value is associated with improper integral Almost all values cannot be calculated accurately, but as we have just seen, with modern computing power this is not difficult. So, for the function =NORMSDIST(z) One, two - and you're done: Now let’s remember one of the key tasks of the topic, namely, find out how to find the probability that a normal random variable will take the value from the interval. Geometrically, this probability is equal to area between the normal curve and the x-axis in the corresponding section: ! Also remembers
, What Here you can use Excel again, but there are a couple of significant “buts”: firstly, it is not always at hand, and secondly, “ready-made” values will most likely raise questions from the teacher. Why? I have talked about this many times before: at one time (and not very long ago) a regular calculator was a luxury, and the “manual” method of solving the problem in question is still preserved in educational literature. Its essence is to standardize values “alpha” and “beta”, that is, reduce the solution to the standard distribution: Note
: the function is easy to obtain from the general case Why is this necessary? The fact is that the values were meticulously calculated by our ancestors and compiled into a special table, which is in many books on terwer. But even more often there is a table of values, which we have already dealt with in Laplace's integral theorem: If we have at our disposal a table of values of the Laplace function I remind you that Answer is required to be given as a percentage, so the calculated probability must be multiplied by 100 and the result provided with a meaningful comment: – with a flight from 5 to 70 m, approximately 15.87% of shells will fall We train on our own: Example 3 The diameter of factory-made bearings is a random variable, normally distributed with a mathematical expectation of 1.5 cm and a standard deviation of 0.04 cm. Find the probability that the size of a randomly selected bearing ranges from 1.4 to 1.6 cm. In the sample solution and below, I will use the Laplace function as the most common option. By the way, note that according to the wording, the ends of the interval can be included in the consideration here. However, this is not critical. And already in this example we encountered a special case - when the interval is symmetrical with respect to the mathematical expectation. In such a situation, it can be written in the form and, using the oddity of the Laplace function, simplify the working formula: It’s good that the solution fits in one line :) The result of this task turned out to be close to unity, but I would like even greater reliability - namely, to find out the boundaries within which the diameter is located almost everyone bearings. Is there any criterion for this? Exists! The question posed is answered by the so-called Its essence is that practically reliable
is the fact that a normally distributed random variable will take a value from the interval Indeed, the probability of deviation from the expected value is less than: In terms of bearings, these are 9973 pieces with a diameter from 1.38 to 1.62 cm and only 27 “substandard” copies. In practical research, the three sigma rule is usually applied in the opposite direction: if statistically It was found that almost all values random variable under study fall within an interval of 6 standard deviations, then there are compelling reasons to believe that this value is distributed according to a normal law. Verification is carried out using theory statistical hypotheses. We continue to solve the harsh Soviet problems: Example 4 The random value of the weighing error is distributed according to the normal law with zero mathematical expectation and a standard deviation of 3 grams. Find the probability that the next weighing will be carried out with an error not exceeding 5 grams in absolute value. Solution very simple. By condition, we immediately note that at the next weighing (something or someone) we will almost 100% get the result with an accuracy of 9 grams. But the problem involves a narrower deviation and according to the formula Answer: The solved problem is fundamentally different from a seemingly similar one. Example 3 lesson about uniform distribution. There was an error rounding measurement results, here we are talking about the random error of the measurements themselves. Such errors arise due to the technical characteristics of the device itself. (the range of acceptable errors is usually indicated in his passport), and also through the fault of the experimenter - when we, for example, “by eye” take readings from the needle of the same scales. Among others, there are also so-called systematic measurement errors. It's already non-random errors that occur due to incorrect setup or operation of the device. For example, unregulated floor scales can steadily “add” kilograms, and the seller systematically weighs down customers. Or it can be calculated not systematically. However, in any case, such an error will not be random, and its expectation is different from zero. …I’m urgently developing a sales training course =) Let’s solve the inverse problem ourselves: Example 5 The diameter of the roller is a random normally distributed random variable, its standard deviation is equal to mm. Find the length of the interval, symmetrical with respect to the mathematical expectation, into which the length of the roller diameter is likely to fall. Point 5* design layout to help. Please note that the mathematical expectation is not known here, but this does not in the least prevent us from solving the problem. And an exam task that I highly recommend to reinforce the material: Example 6 A normally distributed random variable is specified by its parameters (mathematical expectation) and (standard deviation). Required: a) write down the probability density and schematically depict its graph; Such problems are offered everywhere, and over the years of practice I have solved hundreds and hundreds of them. Be sure to practice drawing a drawing by hand and using paper tables;) Well, I’ll look at an example of increased complexity: Example 7 The probability distribution density of a random variable has the form Solution: First of all, let us note that the condition does not say anything about the nature of the random variable. The presence of an exponent in itself does not mean anything: it may turn out, for example, indicative or even arbitrary continuous distribution. And therefore the “normality” of the distribution still needs to be justified: Since the function Here we go. For this select a complete square and organize three-story fraction: Thus: Now let's find the value of the parameter. Since the normal distribution multiplier has the form and , then: Let's build a density graph: As mentioned earlier, examples of probability distributions continuous random variable
X are: Let us give the concept of a normal distribution law, the distribution function of such a law, and the procedure for calculating the probability of a random variable X falling into a certain interval. The length X of a certain part is a random variable distributed according to the normal distribution law, and has an average value of 20 mm and a standard deviation of 0.2 mm. Solution.
A) We find the probability density of a random variable X distributed according to a normal law: provided that m x =20, σ =0.2. b) For a normal distribution of a random variable, the probability of falling into the interval (19.7; 20.3) is determined by: V) We find the probability that the absolute value of the deviation is less than a positive number 0.1: G) Since the probability of a deviation less than 0.1 mm is 0.383, it follows that on average 38.3 parts out of 100 will have such a deviation, i.e. 38.3%. d) Since the percentage of parts whose deviation from the average does not exceed the specified value has increased to 54%, then P(|X-20|< δ) = 0,54. Отсюда следует, что 2Ф(δ/σ) = 0,54, а значит Ф(δ/σ) = 0,27. Using the application ( table 2
), we find δ/σ = 0.74. Hence δ = 0.74*σ = 0.74*0.2 = 0.148 mm. e) Since the required interval is symmetrical with respect to the average value m x = 20, it can be defined as the set of values of X satisfying the inequality 20 − δ< X < 20 + δ или |x − 20| < δ . According to the condition, the probability of finding X in the desired interval is 0.95, which means P(|x − 20|< δ)= 0,95. С другой стороны P(|x − 20| < δ) = 2Ф(δ/σ), следовательно 2Ф(δ/σ) = 0,95, а значит Ф(δ/σ) = 0,475. Using the application ( table 2
), we find δ/σ = 1.96. Hence δ = 1.96*σ = 1.96*0.2 = 0.392. To problems 41-50.
 looks like
looks like  .
. ,
, ,
, ,
, ,
, .
. . Substituting the probability values into this formula, we get
. Substituting the probability values into this formula, we get  ,
, ,
, ,
, ,
, .
.


Probability of a normally distributed random variable falling into a given interval


Normal probability distribution law

Here is a basic view density functions normal probability distribution, and I welcome you to this interesting lesson.
![]() and our graph “moves” 3 units to the left - exactly to the origin of coordinates:
and our graph “moves” 3 units to the left - exactly to the origin of coordinates: 
A normally distributed quantity with zero mathematical expectation received a completely natural name - centered; its density function  – even, and the graph is symmetrical about the ordinate.
– even, and the graph is symmetrical about the ordinate.
Everything is in full accordance with geometric transformations of graphs.![]() . The standard distribution has found wide application in practice, and very soon we will finally understand its purpose.
. The standard distribution has found wide application in practice, and very soon we will finally understand its purpose.
– the probability that a random variable will take a value LESS than the variable that “runs through” all real values to “plus” infinity. , which is equal to some number from the interval .
, which is equal to some number from the interval . standard distribution, the corresponding Excel function generally contains one argument:
standard distribution, the corresponding Excel function generally contains one argument:
The drawing clearly shows the implementation of all distribution function properties, and from the technical nuances here you should pay attention to horizontal asymptotes and the inflection point.
but every time I try to get an approximate value  is unreasonable, and therefore it is more rational to use "light" formula:
is unreasonable, and therefore it is more rational to use "light" formula:
.![]()
 using linear replacements. Then also:
using linear replacements. Then also:
and from the replacement carried out the formula follows: ![]() transition from the values of an arbitrary distribution to the corresponding values of a standard distribution.
transition from the values of an arbitrary distribution to the corresponding values of a standard distribution.
 , then we solve through it:
, then we solve through it:
Fractional values are traditionally rounded to 4 decimal places, as is done in the standard table. And for control there is Point 5 layout.![]() , and to avoid confusion always control, a table of WHAT function is in front of your eyes.
, and to avoid confusion always control, a table of WHAT function is in front of your eyes.
The delta parameter is called deviation from the mathematical expectation, and the double inequality can be “packaged” using module:![]() – the probability that the value of a random variable will deviate from the mathematical expectation by less than .
– the probability that the value of a random variable will deviate from the mathematical expectation by less than .
– the probability that the diameter of a randomly taken bearing differs from 1.5 cm by no more than 0.1 cm.three sigma rule
![]() .
.
or 99.73%![]() :
:![]() – the probability that the next weighing will be carried out with an error not exceeding 5 grams.
– the probability that the next weighing will be carried out with an error not exceeding 5 grams.
b) find the probability that it will take a value from the interval ![]() ;
;
c) find the probability that the absolute value will deviate from no more than ;
d) using the “three sigma” rule, find the values of the random variable.![]() . Find, mathematical expectation, dispersion, distribution function, build density graphs and distribution functions, find.
. Find, mathematical expectation, dispersion, distribution function, build density graphs and distribution functions, find.![]() determined at any real value, and it can be reduced to the form
determined at any real value, and it can be reduced to the form  , then the random variable is distributed according to the normal law.
, then the random variable is distributed according to the normal law.
Be sure to perform a check, returning the indicator to its original form:
, which is what we wanted to see. - By rule of operations with powers"pinch off" And here you can immediately write down the obvious numerical characteristics:
- By rule of operations with powers"pinch off" And here you can immediately write down the obvious numerical characteristics: ![]()
 , from where we express and substitute into our function:
, from where we express and substitute into our function:  , after which we will once again go through the recording with our eyes and make sure that the resulting function has the form
, after which we will once again go through the recording with our eyes and make sure that the resulting function has the form  .
.
and distribution function graph  :
:
If you don’t have Excel or even a regular calculator at hand, then the last graph can easily be built manually! At the point the distribution function takes the value ![]() and here it is
and here it is№
Indicator Normal distribution law Note
Definition
Called normal
probability distribution of a continuous random variable X, whose density has the form
where m x is the mathematical expectation of the random variable X, σ x is the standard deviation
2
Distribution function

Probability
falling into the interval (a;b)


- Laplace integral function
Probability
the fact that the absolute value of the deviation is less than a positive number δ

at m x = 0

An example of solving a problem on the topic “Normal distribution law of a continuous random variable”
Task.
Necessary:
a) write down the expression for the distribution density;
b) find the probability that the length of the part will be between 19.7 and 20.3 mm;
c) find the probability that the deviation does not exceed 0.1 mm;
d) determine what percentage are parts whose deviation from the average value does not exceed 0.1 mm;
e) find what the deviation should be set so that the percentage of parts whose deviation from the average does not exceed the specified value increases to 54%;
f) find an interval symmetrical about the average value in which X will be located with probability 0.95.
Ф((20.3-20)/0.2) – Ф((19.7-20)/0.2) = Ф(0.3/0.2) – Ф(-0.3/0, 2) = 2Ф(0.3/0.2) = 2Ф(1.5) = 2*0.4332 = 0.8664.
We found the value Ф(1.5) = 0.4332 in the appendices, in the table of values of the Laplace integral function Φ(x) ( table 2
)
R(|X-20|< 0,1) = 2Ф(0,1/0,2) = 2Ф(0,5) = 2*0,1915 = 0,383.
We found the value Ф(0.5) = 0.1915 in the appendices, in the table of values of the Laplace integral function Φ(x) ( table 2
)
Search interval
: (20 – 0.392; 20 + 0.392) or (19.608; 20.392).